MS-S1 MAXでローカルAI大規模モデルを動かす完全ガイド
はじめに ― なぜ「ローカルAI」を選ぶのか?
MS-S1 MAXはAMD Ryzen™ AI MAX+ 395プロセッサーと128GB LPDDR5X UMAメモリを搭載し、最大96GBの共有ビデオメモリを動的に割り当て可能です。大規模言語モデルのローカル実行に十分な演算リソースを提供します。
ローカルAIの利点:
- オフライン実行可能(機密データを外部にアップロード不要)
- 低遅延応答
- プライベート環境での安定稼働
一方、クラウドAIの利点は:
- 圧倒的な計算リソース
- 迅速なアップデート
- 複数デバイスの連携
両者は対立関係ではなく、補完関係にあります。使用シーンに応じて柔軟に選択することで、生産性とデータセキュリティを両立できます。
本記事では、実機検証環境:
- Windows 11 24H2
- AMD Adrenalin 25.10 RC
- LM Studio
に基づき、導入から最適化までを解説します。
ステップ1|BIOSのビデオメモリ割り当て最適化
まずはハードウェア性能を最大限引き出します。
目的
- 電源モードを「Performance(パフォーマンスモード)」に設定
- 共有ビデオメモリを96GBに拡張
設定手順
1. PCを再起動 → 電源投入時診断画面(POST)でDelキー連打

2. 詳細設定 → 電力制限設定 → パフォーマンス

3. 詳細設定 → AMD CBS → NBIO共通オプション → GFX設定
iGPU設定 → UMA_SPECIFIED
UMAフレームバッファサイズ → 96GB
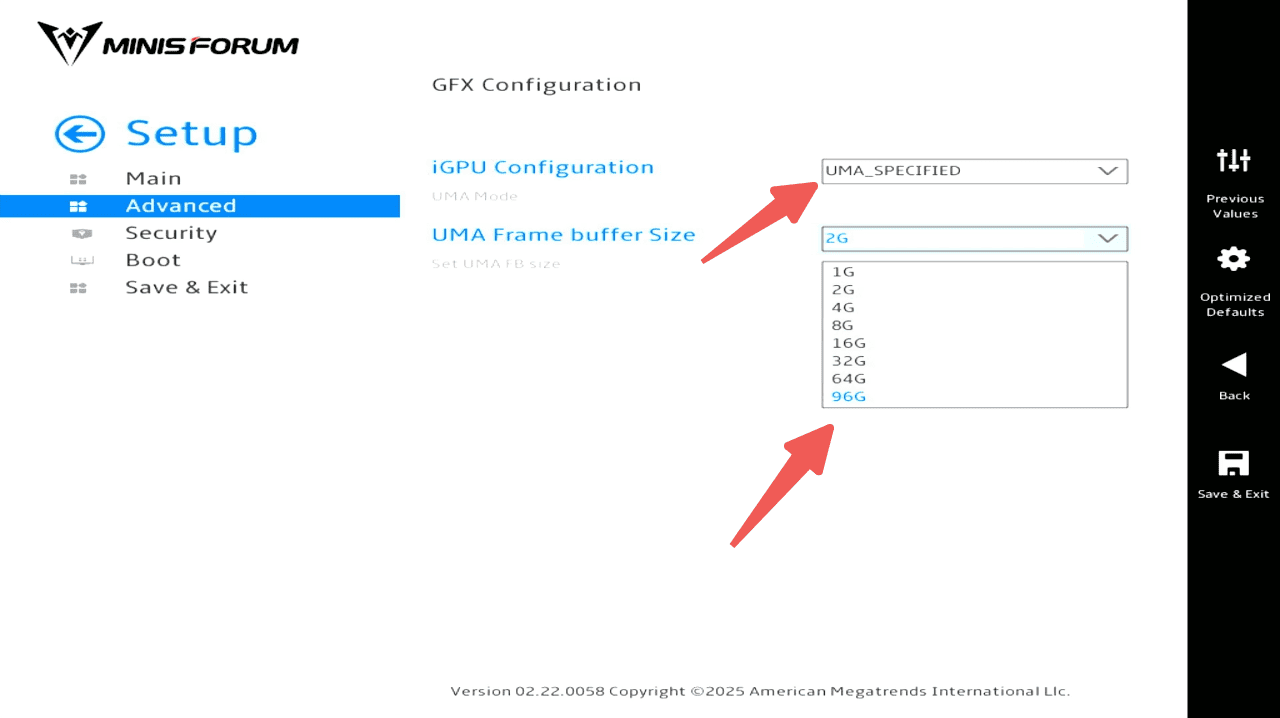
4. F4キーで保存 → 再起動
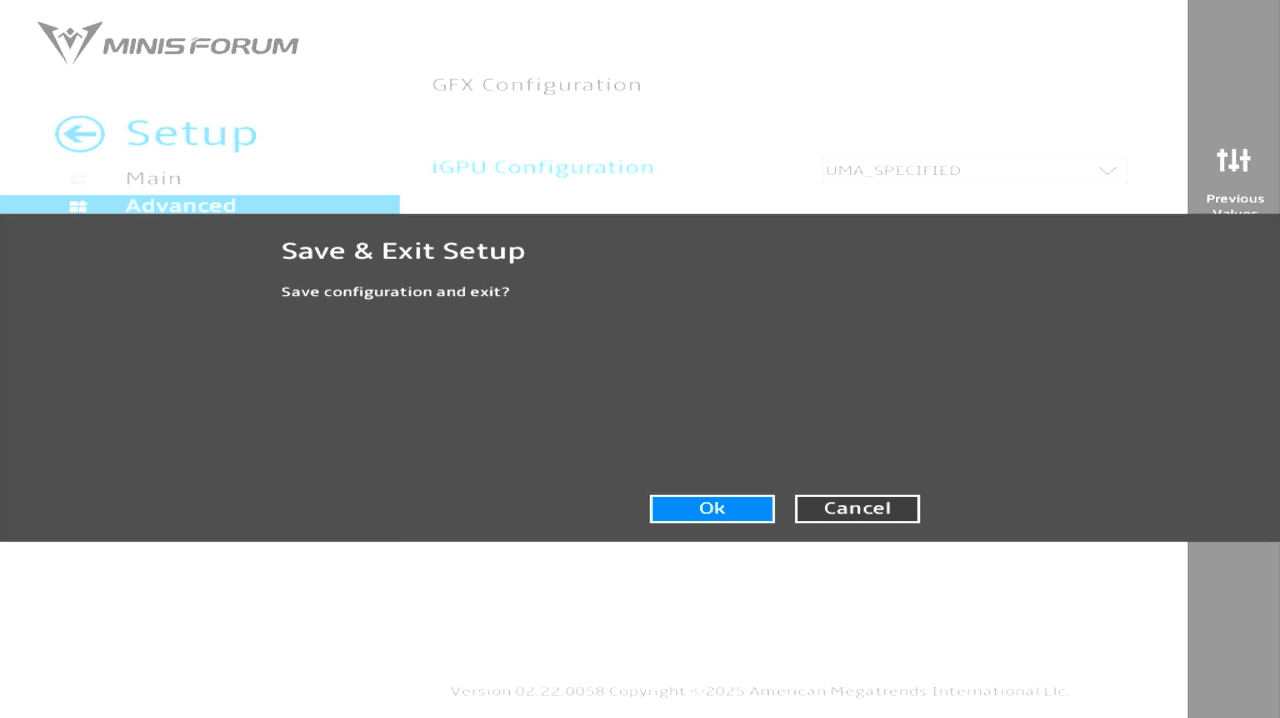
これでAI推論用のVRAMが最大化されます。ビデオメモリ設定が有効になります。
ステップ 2|LM Studio のインストール(Windows 11)
LM Studio は、大規模言語モデルをローカルで実行するソフトウェアです。モデルのダウンロード、管理、オフライン推論をサポートし、個人ユーザーが自身のマシンで AI 対話や開発テストを行うのに適しています。
インストール
1. 公式サイトhttps://lmstudio.ai にアクセスし、Windows 版をダウンロードします。
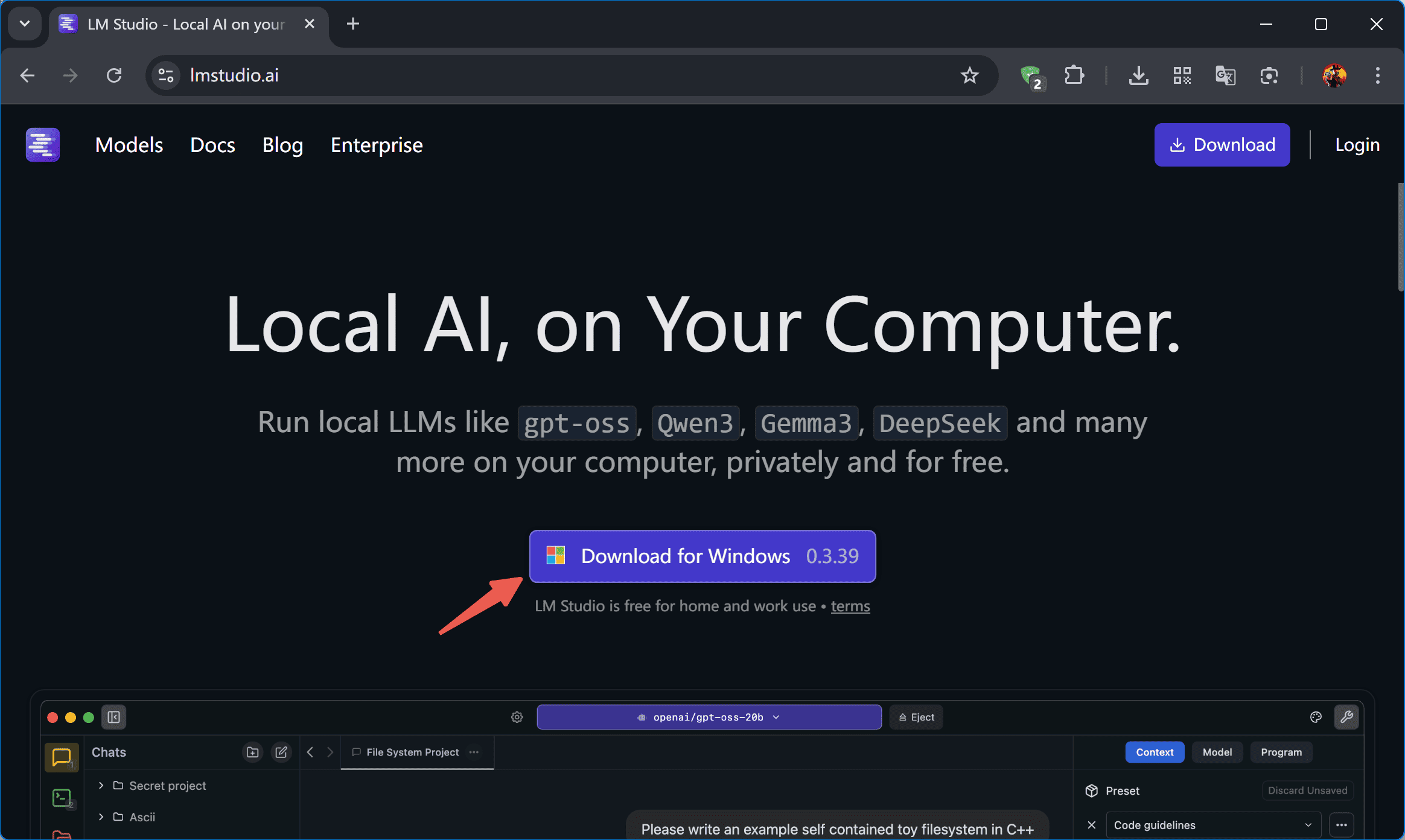
2. インストール手順:インストールパッケージをダブルクリックし、利用規約に同意後、デフォルトのパスを保持したまま「Next」を連続クリックしてインストールを完了します。
3. ソフトウェア起動:「LM Studioの実行」にチェックを入れ「Finish」をクリックします。ログイン不要で使用可能です。
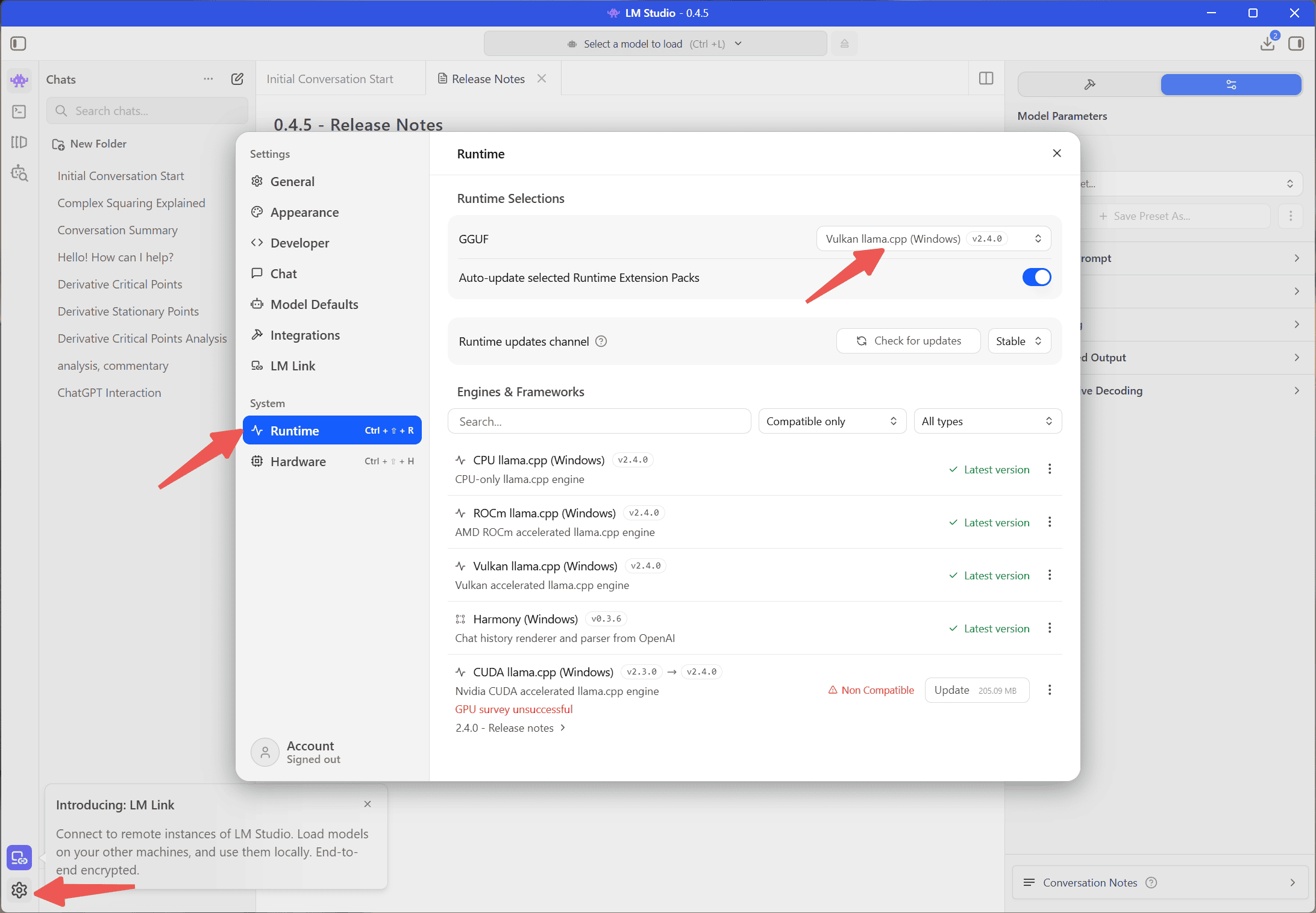
ランタイム設定(重要)
インストール完了後、設定画面でシステム→ランタイムを選択します。これらのオプションはLM Studioが大規模モデルを実行するための「計算エンジン」です。GGUFはVulkan llamaを選択してください。下部に更新情報が表示された場合は、最新版にアップグレードしてください。
選択肢比較
対応ハードウェア
必要コンポーネント
性能特性
すべてのデバイス(CPUのみ使用)
追加コンポーネント不要
最も低速(CPU単体処理)
AMD GPU(単体GPU/一部内蔵GPU)
AMD ROCmドライバ+対応SDK
AMD GPUによる高性能アクセラレーション
AMD GPU(単体GPU/内蔵GPU)
AMD公式グラフィックドライバのみ
AMD GPUによる中〜高性能アクセラレーション
NVIDIA単体GPU
NVIDIA CUDA Toolkit+対応ドライバ
NVIDIA GPUで最適な高速処理
なぜ「Vulkan llama」を選ぶのか?
GPU-OSS-20bモデルを用いた実測比較を実施。データが示す「今すぐVulkanモードに切り替えるべき理由」とは?
tok/sec
初回出力
CPU使用率/GPU使用率
17.24
0.21s
76% / 2%
62.08
0.16s
15% / 89%
61.24
0.24s
13% / 90%
実測データ結論:
CPUおよびROCmと比較により、Windows環境ではVulkanが「高速実行、設定簡便、リソース利用率の高さ」という優位性から最適な選択肢となります。
簡単に言えば、VulkanはROCmに近い高性能を実現しながら、CPU実行のように設定が容易です。Windows環境でAMD GPUを使用しているユーザーにとって、最もバランスの取れた最適解と言えるでしょう。
ステップ3:ローカル大規模モデルダウンロード
単体(スタンドアロン)環境でご利用の場合、以下のモデルを優先的にご選択ください。いずれも MINISFORUM MS-S1 MAX にて動作検証済みです。
推奨理由(簡潔版)
代表的な用途
軽量で導入容易、計算リソース要求が低く、推論能力がバランス良好
ローカル軽量Q&A、オフィス支援、基礎コード生成
7Bより高性能、コンテキストウィンドウが広く、プライベートデプロイに適応
企業ナレッジベースQ&A、複雑な文書分析、技術コンテンツ作成
マルチモーダルフラッグシップ、画像・テキスト認識分析能力に優れ、多様なシナリオに対応
画像とテキストを組み合わせた創作、工業品質検査、伝票/画像認識
Q4-K-M量子化、精度とリソースのバランス、専門能力が突出
高度なプログラミング、科学計算、企業レベルの複雑な推論
大規模パラメータで高性能、デプロイ効率化、オープンソースで微調整可能
企業向けAIプラットフォーム、エージェント開発、クロスドメイン知識応用
※文末付録に出力速度の参考値を掲載しています。
モデルのダウンロード方法
LM Studio メイン画面から操作します。
- 左メニューの【モデルの検索】をクリック
- 【モデル名】を入力(あいまい検索対応)
- 該当モデルを選択し、GGUF形式および対応する量子化バージョンを選択
- 量子化精度を選択(緑色のロケットアイコンが表示されていれば対応)→「ダウンロード」をクリック
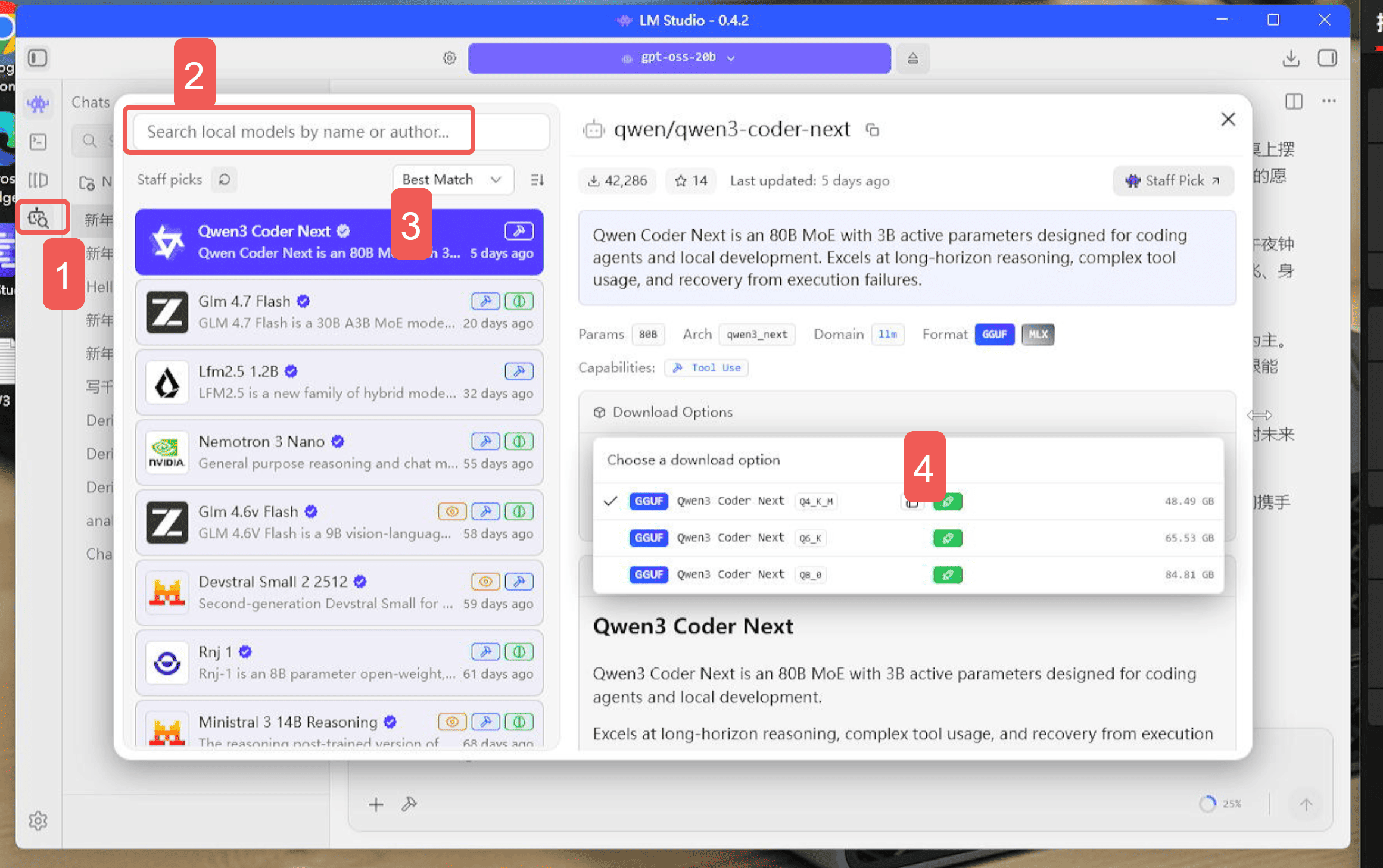
推奨量子化:Q4-K-M
「容量も・品質も・速度も」すべてをバランスよく実現します。
例:7Bモデルの場合、約14GB → 約3.5GBまで圧縮しながら、実用的な出力品質と十分な推論速度を維持します
- モデルの読み込み設定
◦ 「チャット」画面へ移動 → 画面上部「読み込むモデルを選択」をクリック
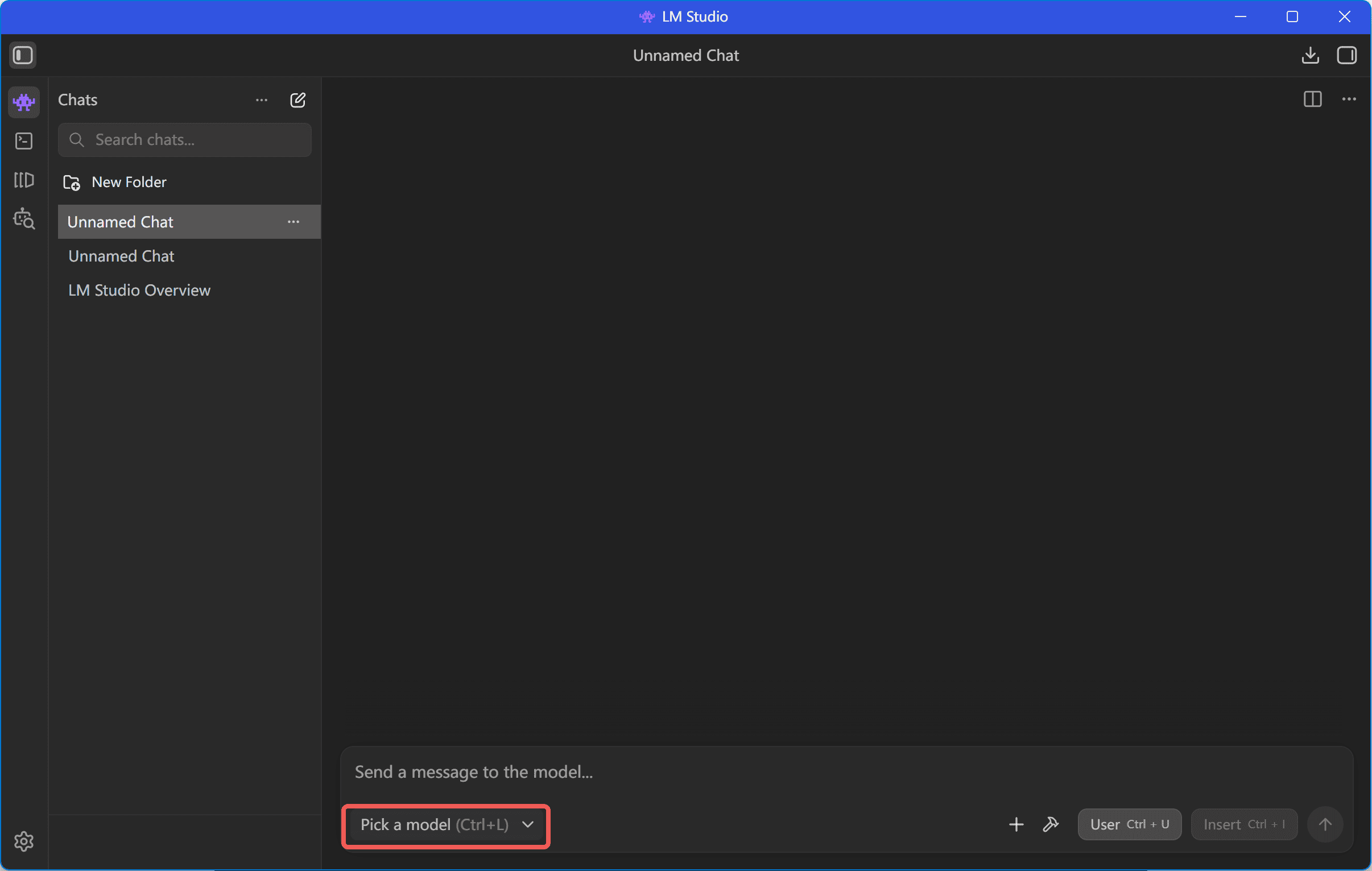
◦ ダウンロード済みモデルを選択 → 「モデルを読み込む」をクリック → 進行バーが完了すれば、対話を開始できます。
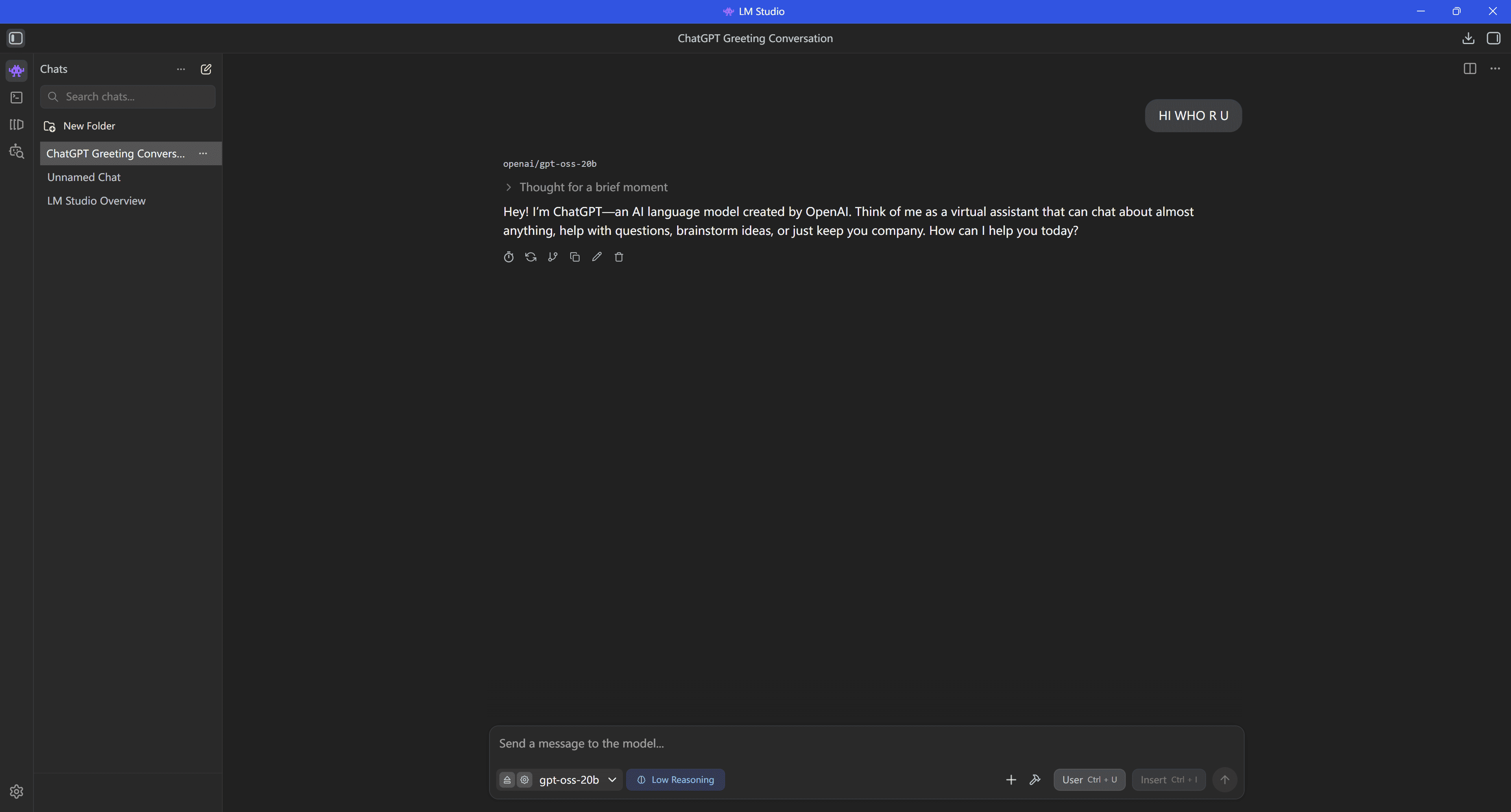
ステップ4:基本対話
- 基本対話
入力欄に指示(例:「随筆を書いてください」)を入力し送信すると、応答が生成されます。 - パラメータ最適化
右側パネルで以下を調整可能:
温度(推奨値:0.7)
最大トークン数(用途に応じて512~4096を設定)
またはシステムプロンプトでモデル役割を定義 - セッション管理
「新しいチャット」で新規セッション作成します。トピック分類をサポートします。
⚠ 重要注意事項・最適化提案
- 放熱対策
大規模モデル実行時は「パフォーマンス」電源モードを維持し、デュアルターボファン+6本ヒートパイプ構成により安定した温度制御を実現します。 - モデル管理
「ローカルモデル」で未使用モデルを削除しストレージ容量を解放してください。 - トークン速度確認方法
画面下部より「パワーユーザーモード」に切り替えることで確認できます。
その他のローカルAIソフトウェア
1. Ollama
- 軽量なオープンソースフレームワーク
- コマンドライン操作が簡潔
- 主流のGGUF/GGMLモデル対応
- OpenWebUIと組み合わせることでChatGPT類似のGUI環境を構築可能
- 2026年 v0.15.1では推論精度とクロスプラットフォーム互換性が向上し、AMD環境への最適化も改善
公式サイト:Ollama
注意事項
Windows版Ollamaは現在CPU推論のみ対応しており、AMD内蔵GPUのVulkanやROCm計算能力は利用できません。
Ryzen AI MAX+395搭載のMS-S1 MAXで、96GB UMAメモリおよびRDNA3.5内蔵GPUを活用したローカル大規模モデル推論を行う場合は、LM Studio(Vulkanバックエンド) または llama.cpp Vulkan環境の直接構築 を推奨します。
一部モデルの出力速度参考値
注:以下のデータは全て銘凡 MS-S1 MAX の 96GB グラフィックメモリ構成におけるローカル実測結果です。異なるドライバーバージョン、モデルの量子化精度、およびモデルアーキテクチャにより速度に差異が生じます。
出力速度(tok/sec)
モデル名
出力速度(tok/sec)
96.59
cogito-v2-preview-Llama-109B-MoE-GGUF
14.18
53.62
Llama4-Scout-17B-16E-Instruct-GGUF
13.94
43
DeepSeek-R1-Distill-Qwen-14B-Q8
13.58
42.33
Qwen3-235B-A22B-Instruct-2507-GGUF-Q2
10.81
32.56
DeepSeek-R1-Distill-Qwen-32B-GGUF
10.04
27.35
Yi-1.5-34B
9.86
24.58
DeepSeek-R1-Distill-Qwen-32B-Q8
6.04
22.25
Llama 3.1 70B
4.8
21.29
DeepSeek-R1-Distill-Llama-70B-GGUF
4.75
4.03








支払い方法は注文画面で選択できます

全国送料無料(沖縄県・北海道を除く)

お届け日の目安

36ヵ月製品長期保証&30 日間返品・返金保証

国内修理サービス・生涯テクニカルサポート
Minisforumメンバー限定特権
全国送料無料(沖縄県・北海道を除く)
›
当店の配送エリアは日本全国です。全国送料無料(沖縄県・北海道を除く)
詳しくは「送料・配送について」をご確認ください。
お届け日の目安
›
- 香港倉庫:2~3営業日以内出荷、お届けまで発送から7〜12日ほどかかります。
- 国内倉庫:2営業日以内出荷、お届けまで発送から2〜3日ほどかかります。
- 整備済製品:2営業日以内出荷、お届けまで発送から2〜3日ほどかかります。
- 予約販売品:商品ページで表示された時間に準じます。
36ヵ月製品長期保証&30 日間返品・返金保証
›
【30 日間返品・返金保証】と【36ヵ月製品長期保証】を提供、製品は保証期間中に、不具合の場合、交換・無償修理するものとします。
モバイルモニターやタブレットなどのスクリーン付き製品は12ヵ月(1年)の保証対応を提供しています。
詳しくは「製品保証について」をご確認ください。
国内修理サービス・生涯テクニカルサポート
›
保証期間内の製品については、無償修理サービスをご提供いたします。
※修理を依頼する前に、必ずアフターサポート(jpstore@minisforum.com)までご連絡ください。ご連絡なく到着された場合、修理をお受けできない場合がございますのでご了承ください。
修理住所:
〒409-3801
山梨県中央市中楯753-2、3階3F
753-2,Nakadate, Chuo-shi, Yamanashi-Prefecture
担当者:Paul. Lin